
Reinforcement learning scaling might incentivise hidden reasoning architectures for AI
Another reason really competent AI might lie to you

In short: the transformer architecture brought massive scale to AI, and also provided partial guarantees of ‘reasoning out loud’, an unprecedentedly interpretable situation for AI. Reinforcement learning (RL) may be less compatible with the transformer architecture, and RL is being scaled up at the frontier of AI. So we might see the end of the ‘reasoning out loud’ era for AI.
This is part 2 of a series about LLM architecture and some implications for reasoning and transparency. Part 1 explained how we got where we are. Here, we look at where we might be going soon — does visible reasoning go away?
Hidden reasoning
There’s a term that’s caught on somewhat to describe deep learning: inscrutable. Deep learning centrally relies on (large) neural networks, whose workings are famously impenetrable to those training them or operating them alike. I won’t expand much on that here.1
The key thing is: a neural network takes inputs, converts them into an opaque and idiosyncratic internal language, then computes outputs. The arcane bit in the middle goes by many names: deep embeddings, neuralese, activation space, latent space. I’ll call it hidden reasoning.
Humans do this too, of course! You can’t tell what someone’s thinking or planning unless they tell you and they’re honest about it. (And apart from the surface thoughts we’re aware of, we don’t even know most of what’s going on in our own subconscious.)
A dash (em-dash?) of luck: ‘thinking out loud’
Hidden reasoning is concerning. Worst case, we have scheming AIs. Best case, it’s hard to know how much to trust the outputs — not because you think the AI is deceiving you, but because you just don’t know what it’s taking account of, and how, in its decisions.
But we got quite lucky for a spell! Scaling language models turned out to be the easiest path to general purpose reasoning AI, and not only that, but the famed ‘attention is all you need’ transformer architecture which got us here places substantial limits on the amount of hidden reasoning the AI does.
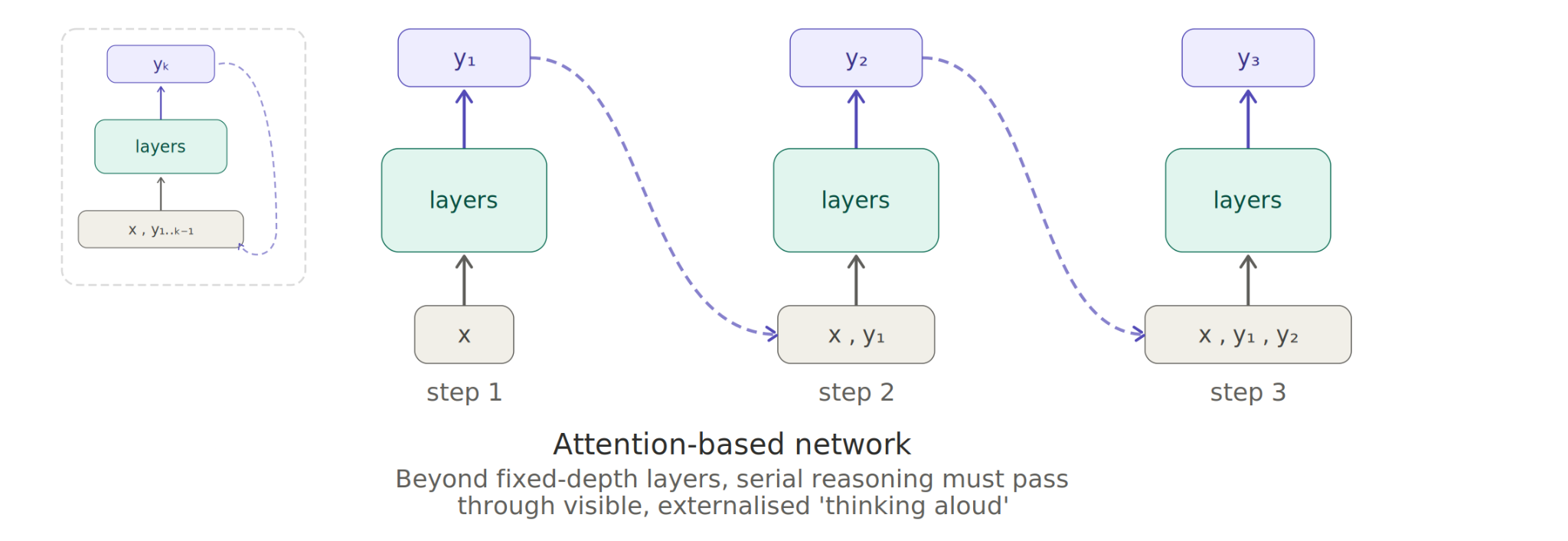
But limited reasoning is limiting! People want AI to be able to do things. The obvious solution is to employ visible reasoning. This is already something humans do all the time — from ‘thinking aloud’ to writing notes (or whole textbooks!), sharing thoughts with others, brainstorming, using computers, databases, ‘tools for thought’, and so on.
One of the most effective classes of improvements to AI reasoning in this paradigm is encouraging it2 to ‘think aloud’ things like, ‘wait, is that right?’, ‘let me consider more possibilities’, ‘I should double check that’, and the like.
So, status quo, frontier AI is increasingly good at reasoning, largely as a consequence of ‘thinking out loud’ more and more. There’s a mostly human-readable trace of what it’s thinking.3 Although we don’t know exactly how much reasoning can be crammed into the hidden parts,4 it’s a matter of sheer structural message-passing necessity that any more than that must go via the ‘out loud’ pathway.
This is a good thing for oversight of AI, because they are capable of scheming under the right conditions, but so far usually only by blurting out all their plans as they think aloud!
Aside: keeping visible reasoning faithful
Of course, even if the AI does most of its reasoning in externalised text, there’s no guarantee in theory that it’s using human language the way we expect.
This is why researchers call this kind of monitorability a ‘Fragile Opportunity for AI Safety’, noting with concern that reasoning models ‘don’t always say what they think’ and proposing ways to protect and improve this fragile opportunity.
The cake is a lie: reinforcement learning back in style
Recall LeCun’s ‘cake’ analogy for AI training. The vast majority goes to self-supervised ‘what comes next’ prediction, with character- and rules-tuning relegated mostly to a ‘cherry on top’. To terribly oversimplify, this gives some reason to expect most ‘out loud’ reasoning to be essentially faithful at this stage. Why? Most of the training examples of human-looking reasoning are records of actual humans reasoning!5
Those of us with background in reinforcement learning and agent foundations always considered the relegation of RL to a ‘cherry on top’ somewhat suspect. LeCun’s prediction held for a few years — but by 2024 general AI developers were starting to really scale up the RL, and here in 2026 it may be reaching on par with self-supervised pretraining. Some cherry!
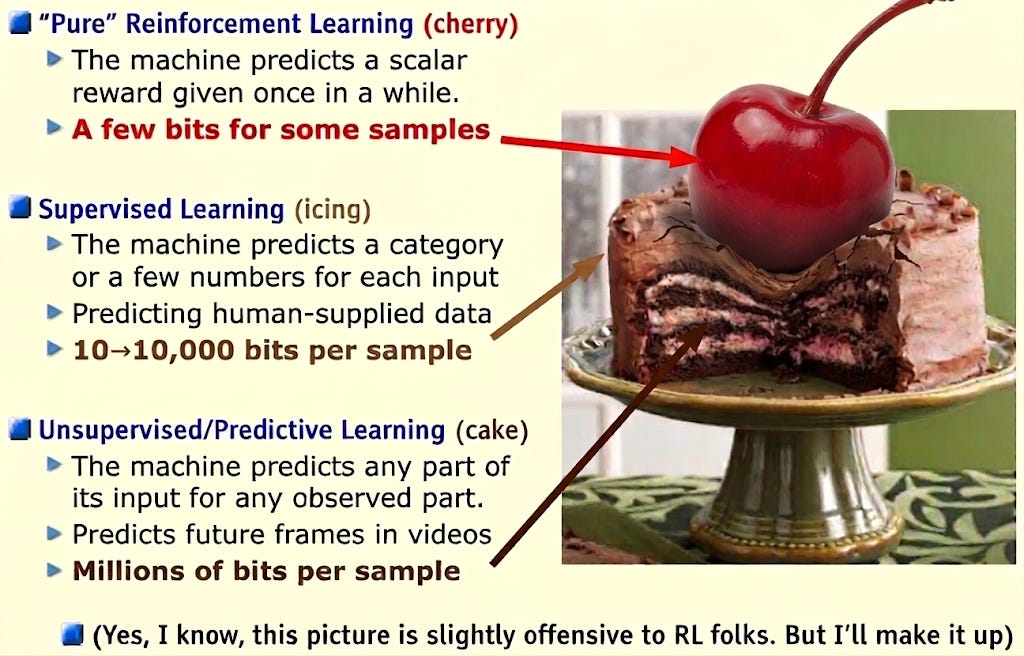
This abundance of RL training over diverse tasks is probably most of what’s differentiating competitive frontier capabilities in AI today.
Reinforcement learning’s serial training penalty
When you’re running a machine language model, you generally have to wait for it to say one thing before it can say the next.6 Running a model through RL training is even more demanding: you have to wait for it to do something and gather the result before it can do the next. No shortcuts.
This means RL on attention-only transformer language models is dramatically handicapped compared to self-supervised pretraining. (Recall that attention-only bursts open the serial bottleneck for self-supervised learning in particular, kicking off the deep learning x big data language model revolution.)
Said another way, if most of your training is self-supervised and only a little is RL, attention-only architecture is an incredible efficiency boon.7 But once RL is a meaningful fraction of training, the scalability benefits of attention-only self-supervised pretraining begin to dwindle in comparison.
This is a large part of why companies were slow, reluctant to scale RL until they ‘had to’. But it now looks like they probably have to.
Return of the recurrent network?
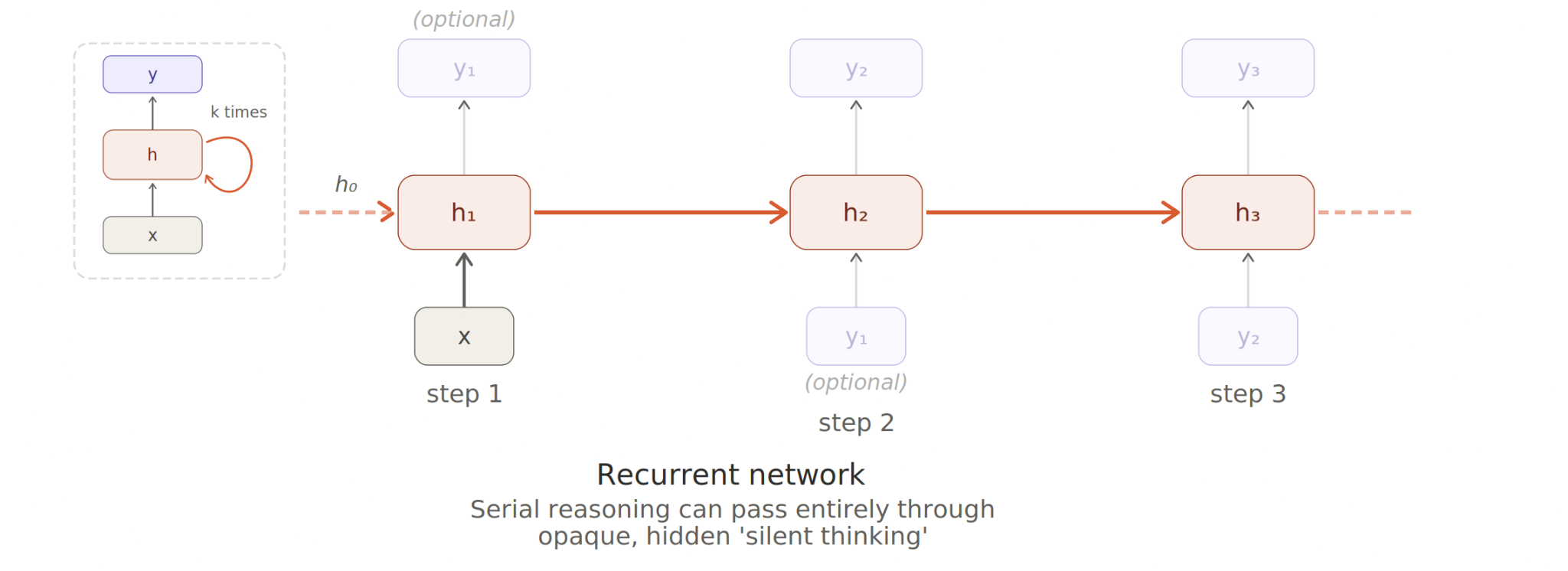
Because RL has to ‘wait’ for things to unfold sequentially, it ‘might as well’ make use of fully recurrent messages (‘hidden reasoning’) if it can.
In fact, because the hidden reasoning occurs in neural activations rather than mere human-readable text output, it’s actually got far more information capacity. That’s a further point in favour of recurrent connections.
Speculatively, developers might somehow get the ‘best’ of both worlds by introducing recurrent messages for RL training stages but skipping them for self-supervised learning.
Does ‘thinking out loud’ go away?
Putting things together: developers are turning to RL at serious scale — this is a novel demand on frontier general AI. Previous developments leant on massive self-supervised pretraining and little else. That made the attention-only transformer architecture indispensable for training efficiency. The transformer also very conveniently gave us ‘reasoning out loud’ as the closest thing to interpretable AI we’ve perhaps ever had. That’s generally considered convenient for safety: a ‘fragile opportunity’.
If RL scale eats up the efficiencies of attention-only (non-recurrent) training, and companies continue to be willing to pay increasing costs for frontier training, they may turn to ‘hidden reasoning’ architectures, including fully recurrent hidden messages — after all, these plausibly benefit the AI’s competence.
This isn’t purely speculative: ‘latent reasoning’ is an active research area in AI, enough so that a 30-author, 40-page survey of the field was published in 2025.
Potential saving benefits of visible reasoning
There are obvious benefits to sharing some reasoning ‘out loud’.
Sharing what you’re thinking about — in the AI case, not only with ‘copies of yourself’ which have the same internal thought-language, but also with heterogeneous AI systems and humans — is often beneficial, at least with friendly collaborators. Curiously, it might be especially useful to be provably largely honest in a way that humans can’t achieve. Structural, architectural constraints which rule out certain kinds (or degrees) of conniving may point in this direction. That’s fairly niche, though, and has various other difficult dependencies.
The case of humans is instructive: to boost our reasoning, we don’t just ‘think out loud’; we often use reams of scratch paper, digital notes, archives, databases, and so on. AI systems with the right tools can make use of systems like this too. Now, for AI, such systems could be written entirely in idiosyncratic neuralese or stegotext: this might have some capacity and representational benefits, but would act heavily against compounding and maintenance and sharing. I wouldn’t be surprised to see some of both: ‘personal’ dense idiosyncratic jottings, and ‘external’ or ‘long-term’ more natural records.
I don’t think these benefits say you should only reason out loud.
There are also the aforementioned safety and oversight benefits. While ‘capability’ and ‘safety’ tradeoffs are often a little murky in AI, this might be one of the most clear cut cases where they act against each other. I’d advise frontier AI developers to refrain from throwing away the benefits of overseeable AI reasoning without understanding the implications very clearly.
Does it even matter?
I’m speculating somewhat here — in particular, besides the crude gross comparison between self-supervised and RL expenditure, I haven’t ‘run the numbers’ on the specific implications of different language model architecture setups. The serial training penalty of RL may bite imminently, or it may be some distance out. Someone more familiar with precise details of AI training expenditure or training regimes might have more to say there. I expect that within AI development companies there are people already researching these things.
More generally, I have tended to be somewhat cynical about deployers of AI systems actually bothering to look at the bounteous reasoning traces their AI systems produce anyway! Surely the responsible ones at least try to, or (of course) they get other AI systems to do so. But if the cat is out of the bag with AI development, it’s difficult to imagine all such developers and deployers being responsible.
Conversely, maybe we can do much better than merely relying on architectural semi-guarantees on reasoning transparency! Epistemic virtue evaluations (and associated training) may be able to drive much more clarity and honesty than mere thinking out loud. And structural, compounding knowledge-bases curated with help from AI and grounding more AI’s outputs might be a path to truly trustworthy communication and learning.
Note that whole fields of explainable AI and AI interpretability exist, with many open research agendas. People are trying, bless them! They have made nonzero progress! But neural networks are still basically impenetrable.
I say ‘encouraging’ to encompass all of training, prompting via input, forcing via injected context, or other steering injections.
The company serving the AI might hide it from you. Whoever runs the AI may hide it from you (perhaps just showing you final outputs, or even passing them off as their own production). But at least the reasoning is out there, externalised for someone to look over in principle… if they can be bothered. (Maybe they’ll get their AI to do it!)
Perhaps something like a few minutes’-worth of mathematical reasoning without making notes, and perhaps a few ‘steps’ of logic.
There are reasons even this comes apart — records of human writing and speech are not usually records of human thought. Nowadays, some of the records are of AI writing from earlier generations! But there are enough basically faithful examples of ‘thinking out loud’ and ‘reasoning clearly’ that when you encourage a mostly-pretrained AI to reason out loud really really comprehensively, it seems to mostly do that in a human-readable way.
There are some partial ways around this, but on the whole it’s right.
Consider Amdahl’s law: the self-supervised part is ridiculously parallelisable — it’s ‘optimised’ — and the RL part isn’t. When RL is small, the overall boost is very large.