
Gato’s Generalisation: Predictions and Experiments I’d Like to See

I’m deliberately inhabiting a devil’s advocate mindset because that perspective seems to be missing from the conversations I’ve witnessed. My actual fully-reflective median takeaway might differ.
My covid has made writing difficult at the moment, and I haven’t had the energy to gather citations or fully explain the detail for some of the assertions in this post.
I believe (for various reasons not detailed here) that qualitative advances in general agentic performance from artificial systems are likely this decade and next—I just don’t think Gato represents progress in that direction. I’m not particularly surprised by anything in the Gato paper[1]. Naturally, then, I’m against hyperbole around the capabilities demonstrated.
There is not enough information in the paper to say either way, but it may be the case that Gato represents a novel and cutting-edge distillation technique and if so, I would prefer if it were framed that way than as an increment towards generalisation ability of artificial agents!
The authors do a reasonable job of reporting their experiments (though I sense some motivated reasoning in the presentation of some results[2]), but the PR version of the story (at least as I have encountered it) departs from the mostly-honest paper itself[3].
I focus here almost entirely on sequential control, since that is the aspect of the discussion around the Gato paper which seems most clouded, while being at the centre of the purported generalisation, and in which I have the most interest and expertise.
Techniques and phenomena
We’ve known for many years that attention mechanisms (early 2010s) allow parameter sharing over sequences and over inputs of variable size/shape, that behavioural cloning (early 1990s?) often works with enough expert examples, that representation transfer (embeddings, early 2010s?) works, and that fine-tuning parameters (2000s? 2010s?) is faster than learning from scratch.
What should the key empirical takeaway be?
In my reading, if you subtract the already-known phenomena, and pass over the mostly-ignored distillation aspect, there is an important empirical finding in the Gato paper. I’m not sure if it’s novel per se, but it probably is at this scale in this domain.
Namely, in our current systems, fine-tuning is typically fast when pretraining includes closely related tasks (e.g.DM Control Suite and Meta-World), slow when pretraining does not include closely related tasks (e.g. every control task without domain-relevant pretraining, including RGB stacking), and actively worse when pretraining includes distracting unrelated tasks (e.g. the single held-out Atari task, Atari boxing, is distracted by any pretraining in the reported experiments!).
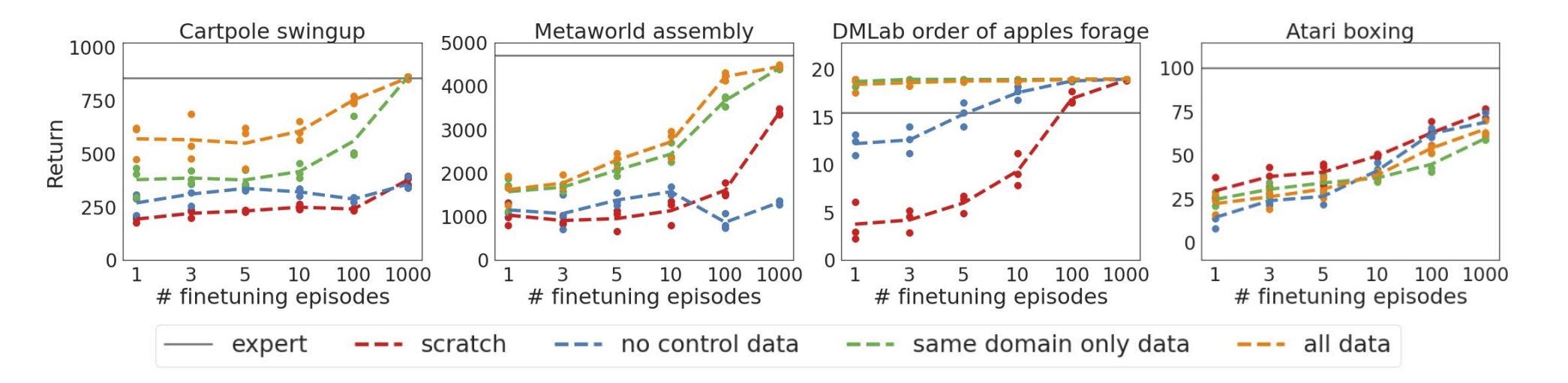
Fine-tuning progress demonstrating benefit of closely related pretraining, and neutrality or harm of unrelated pretraining
Fine-tuning progress demonstrating benefit of closely related pretraining, and neutrality of unrelated pretraining
There is the additional novelty of goal-conditioning by context-prompting with a completed task, both during training and deployment (section 2 of the paper). Goal-conditioning is an interesting and relatively recent area of research. As with all such techniques I am aware of, this conditioning technique requires explicit presentation of a goal state which is structurally very similar to those seen in training. As briefly discussed in the paper, this could be applicable in the context of perceptual variation for closed-environment control (like some industrial robotics tasks) but this is fundamentally separate from general agency.
Comparison to other results regarding sequential control
Let’s consider a comparison to the DQN papers published in NIPS and Nature in 2013.
Data efficiency
Note that the Gato control tasks were all learned by behavioural cloning on pretrained expert policies, each of which used a dedicated specific learning architecture, and were in many cases exposed to >10^8 environment steps for training each (depending on task; more on Atari; see appendix F of the paper).
Compare Nature DQN, which had a quarter of the environment interaction experience per task on Atari.
Parameter count
Recall that the NIPS DQN paper learned Atari games without demonstrations (albeit per-game) using networks with less than a million parameters, and the final paper published in Nature used parameter counts little over a million. That’s three orders of magnitude less than the larger Gato network (1.18B) and two-and-a-half less than the medium one used in ablations (364M), and this is before serious algorithmic and architectural optimisation investments started in deep RL—so we’re not looking at a small network with surprising capabilities here, but rather a decently-sized network for the domains in question.
NIPS DQN[4]
type spec shape params
0 input 84x84 * 4 channels 84x84x4 -
1 conv 8x8 stride 4 * 16 channels 19x19x16 16*(8*8*4) = 2^12
2 conv 4x4 stride 2 * 32 channels 8x8x32 32*(4*4*16) = 2^13
3 ffn 256 256 256*(8*8*32) = 2^19
4 output <= 18 <= 18 <= 18*256 ~= 2^12
Nature DQN[5]
type spec shape params
0 input 84x84 * 4 channels 84x84x4 -
1 conv 8x8 stride 4 * 32 channels 19x19x32 32*(8*8*4) = 2^13
2 conv 4x4 stride 2 * 64 channels 8x8x64 64*(4*4*32) = 2^15
3 conv 3x3 stride 1 * 64 channels 6x6x64 64*(3*3*64) ~= 2^15
4 ffn 512 512 512*(6*6*64) ~= 2^20
5 output <= 18 <= 18 <= 18*512 ~= 2^13
(I assumed here they didn’t use padding on the conv layers, and I ignored bias terms. The overall parameter count doesn’t change much either way.)
Note also that the original DQN was able to achieve that performance while computing over only the 4 most recent frames, while the attention mechanism (and the recurrent mechanisms used in the expert policies) for the Gato paper will have access to much more history than that per decision step (perhaps ~50 frames for Gato, based on the context length of 1024 and image-tokenisation into 20 patches; see sections 2.3 and C.3).
Embeddings
In the Gato paper ResNet embeddings are also used for the image patches, but I can’t find the details of these components specified—perhaps their parameters are in the low or fractional millions and either omitted from or absorbed into the parameter counts? But given that they’re using residual connections, these image embeddings alone are presumably deeper than the DQN networks, if not larger.
Comparison conclusion
DQN used orders of magnitude fewer parameters, multiples less environment interaction experience, and orders of magnitude less compute per step than Gato, on Atari.
Nature DQN Atari is a collection of neural networks. Gato’s primary artefact is one (much much bigger) neural network (if you ignore the many individual neural networks used to learn the expert policies prior to behaviour cloning.)
Generalist or multi-purpose?
There are also learned embeddings for ‘local position’ (image-patch position and shape-relative embeddings for other input types). This is a sensible move and possibly the part of the paper which deserves to be called ‘generalist’ (as in, a general attention-based ML architecture).
In light of the above observations and comparisons, and some additional speculation detailed below, I consider the Gato artefacts (‘agents’) no more general than the collection of experts they were distilled from, though certainly they provide a multi-purpose model and demonstrate that distillation of multiple tasks into the same ML artefact is possible if you tag things appropriately and take care during training to avoid catastrophic forgetting.
Speculation
My best guess is that the domains and tasks trained have easily-detectable ‘embedding signatures’ via a combination of
explicit modality-dependent embedding (images vs text vs actions)
domain-dependent position encoding ‘signatures’ in the token-stream
Thus, I imagine as the Gato training algorithm learns it is doing something like:
learning good embeddings for different input modalities (as a consequence of diverse training data)
extracting the ‘embedding signatures’ and internally tagging domains and tasks, for downstream ‘switching’
(most speculative) mostly routing domains and tasks to be learned/memorised ‘separately’
doing the usual attention-based sequence prediction thing on each domain/task
Of course it won’t be as clean as this, but I bet a really good interpretabilitator would pull out some structure resembling the above pattern[6].
To the extent that Gato artefacts provide ‘generalisation’ capability, I expect it to be through transfer of good-quality representation embeddings learned over many related tasks, computed over the combination of the explicit token and position embeddings and the earlier layers of the attention network.
When domain- and task-specific feature representations are available, supervised fine-tuning on expert demonstrations should naturally be expected to rapidly and reliably recover good performance.
Any residual generalisation benefits from fine-tuning of cross-domain pretraining vs training-from-scratch may come from ‘burn in’ of the parameter space, effectively spending some training cycles getting it into a better ‘initialisation’ than the one that comes out of the box.
I do not expect any generalisation to come from anything resembling a general strategic, agentic, or planning core. I don’t believe any of the Gato artefacts houses such a thing. For what it’s worth, reading the paper, I get the impression that most of the authors also take this last position.
Experiments I’d like to see
More hold-outs?
Purporting to demonstrate agentic generalisation demands more than four held-out tasks, and perhaps more than one held-out Atari task. Of course it costs money and time to run these experiments, so they probably have not been tried yet.
Ideally there would also be a demonstration on actually out of distribution tasks. If there were any meaningful success here, my mind would be substantially changed, considering the reported negative generalisation performance on the single held-out Atari game.
Compute comparison between experts and distilled version
A comparison I would like to see would be between the Gato artefacts and the various expert policy models they were distilled from on
parameter count
runtime compute per step
If these comparisons are favourable, as noted above, it may be that Gato is best thought of as a novel technique for distilling policies and other expert behaviour, which would be an interesting result.
My best guess is that these comparisons are mostly not favourable to the Gato artefacts, but I’d be interested by counter evidence.
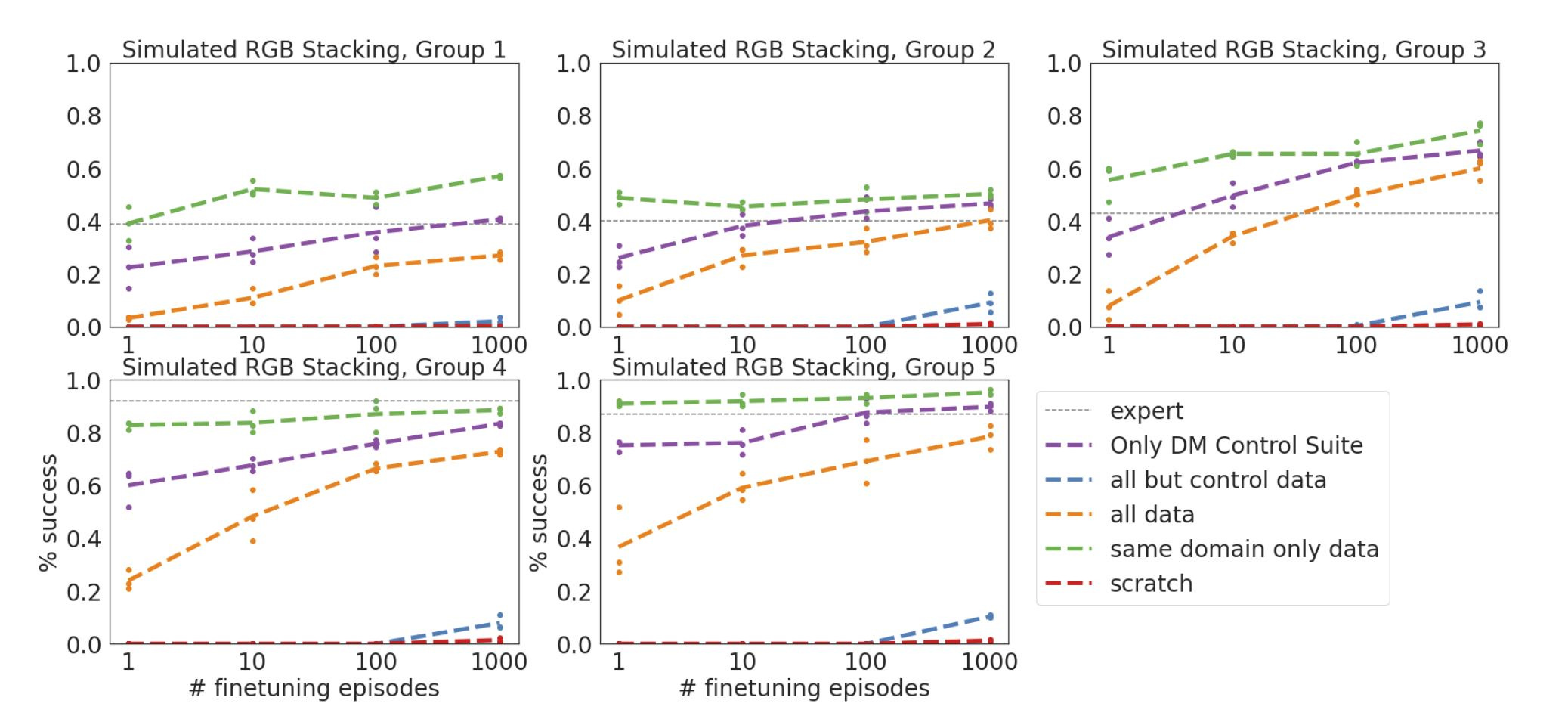
Ablation of image pretraining
For some tasks in the Gato paper, there was some residual benefit to pretraining on no control data″ aka all but control data″, compared to training from scratch. I imagine almost all of this benefit comes from pretraining the image embeddings. Note that the authors also speculate
agents in the DM Lab environment are fed images which, despite being simulated, are natural looking. Therefore, transfer from image captioning or visual grounded question answering tasks is possible.
This could be falsified by introducing new ablation categories for no image data″ (include control but not image-based control) and no control or image data″[7]. In light of the above quote, I’m somewhat surprised not to find experiments like this in the paper.
Burn-in of parameter space
Initialisation of network weights is an area of experimentation and study; many approaches and heuristics exist, some of which will lend themselves to better learning rates than others.
A network at initialisation will have poorer weight/parameter settings than after some training(citation needed).
Here I’m referring to a fuzzy concept for which I do not have good technical language. Obviously parameters at initialisation are worse than after training (assuming training better than a random walk). But in addition to what we might think of as ‘fine grained’ learning and memorisation, there are also ‘coarse grained’ properties of initialisation which are poor, not specifically because they produce incorrect results, but because they are not yet in a good, readily-trainable region of parameter space.
For concreteness, consider properties like ‘overall magnitudes’ and ‘diversity of weights’ and the other heuristic properties which initialisation approaches are supposed to help with. The phenomenon of some amount of training cycles being spent ‘burning in’ the network is a common intuition in machine learning as practiced.
I don’t have any experiment in mind for this one!
Perhaps ablating relative to amount of ‘burn in’ training on totally-unrelated data? But results of such experiments seem insufficiently-hypothesis-splitting to me: evidence for ‘burn in’ might also look like evidence for learning ‘general transferrable agency’. I don’t think the latter is what’s happening, but the whole point of an experiment would be to disambiguate those hypotheses.
Uncovering implicit domain signatures
Evidence for ‘domain signatures’ or ‘task signatures’ would be the ability to ‘easily’ classify domain or task.
How many layers of the network’s activations are required to classify domain/task by linear regression or small single-hidden-layer FFN?
taking padded single ‘timestep frames’ as input
taking n tokens as input
are the post-embedding raw tokens enough?
what about individual early layers of the attention network?
what about individual late layers of the attention network?
is there a network depth boundary where there’s a phase transition?
how many principal components can we throw away and still classify?
how much distortion can we add and still classify? (e.g. squash activations to sign)
Explicit identification of domain- and task-tagging
Interpretability techniques applied to directions in the layer activations.
Can we uncover layer activation directions which correspond to domain- and task-tagging?
note that the tags and switching are likely to be rotated with respect to the canonical basis of the vector space of activations. See Features in Olah et al—Zoom In; transformer attention networks in particular impose no real constraint on the orientation of features
so you might not find particular attention heads or weights dedicated to particular domains, but rather something more cryptic
can we locate domain- or task-specific highly-active directions?
what layers are they in?
is there a depth boundary where there’s a phase transition?
Conclusion
There is a lot of great engineering reflected in the Gato paper, but the artefacts admit more potentially-revealing experiments than have yet been performed.
Depending on details not revealed in the paper, the techniques may represent a novel practical model-distillation technique.
I don’t see evidence for the Gato artefacts being generalists (or agents, in a strict sense, for that matter), and my opinion is that claims to this effect are at best hyperbolic or confused. Readers (and writers) should take care to understand the multiple different possible connotations of words like ‘general’ and ‘agent’.
On the other hand, I do expect the discourse and framing to be such that the Gato paper is inevitably cited in any work from now on which does make progress in that direction (along with anything else which purports to).
Some examples I gathered on a subsequent reading:
Section 4.1: (emphasis mine)
For the most difficult task, called BossLevel, Gato scores 75%
(footnote mentions that other tasks in fact scored lower)
Section 5.2: (emphasis mine)
In this section we want to answer the following question: Can our agent be used to solve a completely new task efficiently? For this reason, we held-out all data for four tasks from our pretraining set
Section 5.5:
The specialist Atari agent outperforms our generalist agent Gato, which achieved super-human performance on 23 games. It suggests that scaling Gato may result in even better performance.
Appendix E:
We evaluate agent every 100 learning steps. Each evaluation reports the average of 10 runs of a given checkpoint. The moving average of 5 such scores is computed (to gather 50 runs together). The final fine-tuning performance is defined as the maximum of these smoothed scores.
Based on professional experience, I react also (perhaps unreasonably) cynically to the density of phraseology using the ‘generalist agent’ bigram, and to the conflation of the techniques, training methods, architectures, and trained artefacts in the paper and public discussions under a single anthropomorphising moniker, ‘Gato’.
DeepMind publications usually read with much less of the marketing and hype aesthetic than this.
Mnih et al—Playing Atari with Deep Reinforcement Learning https://arxiv.org/pdf/1312.5602v1.pdf
Mnih et al—Human-level control through deep reinforcement learning https://www.datascienceassn.org/sites/default/files/Human-level Control Through Deep Reinforcement Learning.pdf
I suspect Transformer-style attention networks may be particularly well-suited to doing this sort of context-signature-tagging and switching-routing-separation and this is a large part of my model of how they work
Although see speculation on burn-in, which might confound such an experiment